Performance
Benchmark Types
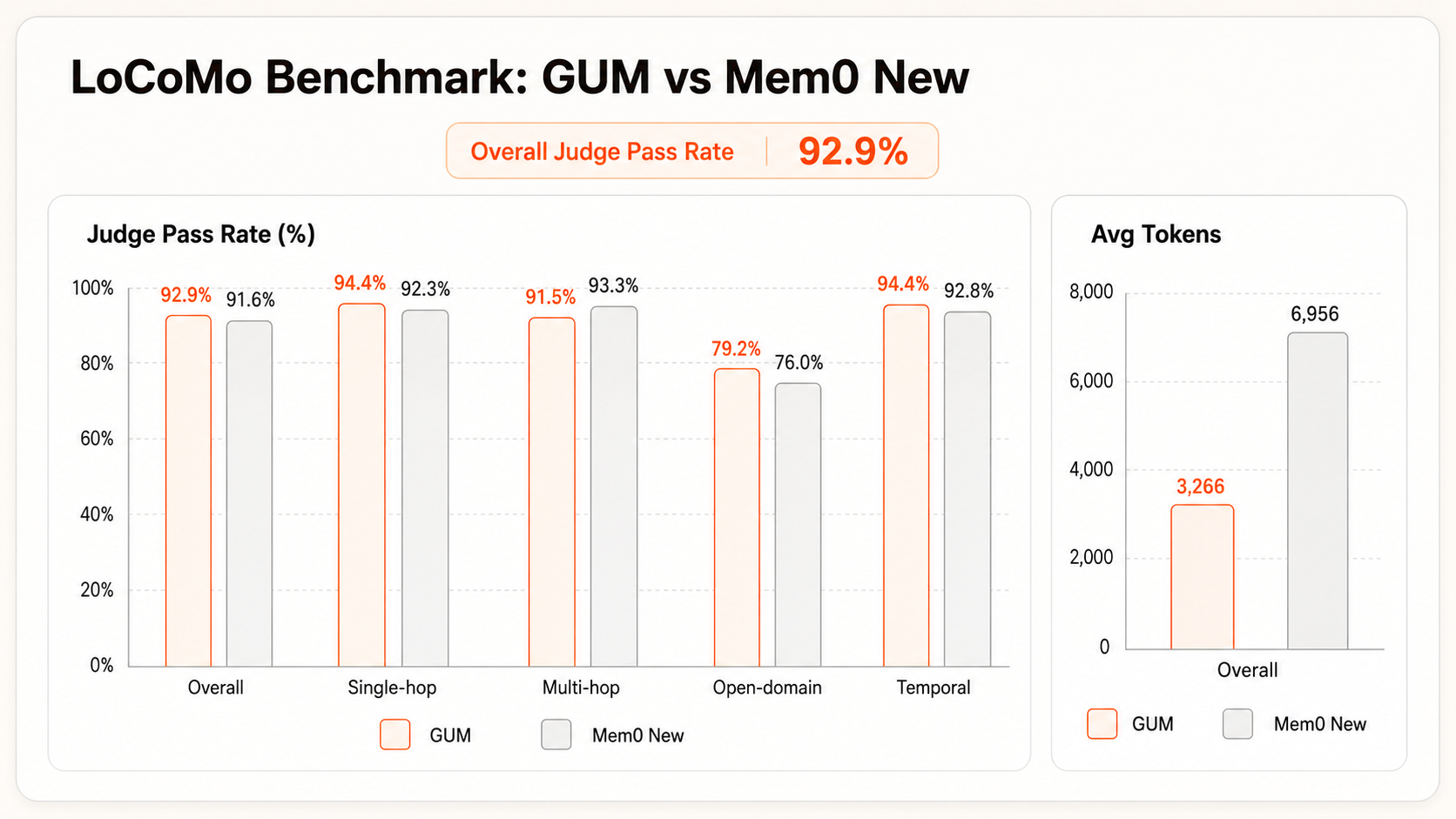
LoCoMo
LoCoMo is a commonly used benchmark for long-conversation memory. It covers cross-turn, cross-topic, and temporal questions, making it useful for testing whether an Agent can recall stable user facts and events from long histories. Mem0 is one of the more widely used Agent Memory products, so it provides a useful baseline for comparing recall quality and context cost.
MemSkill is a 2026 Agent Memory research paper that reframes memory extraction, consolidation, and revision as learnable and evolvable memory skills rather than fixed rules. The paper evaluates memory systems on LoCoMo, LongMemEval, and other tasks, and includes Mem0, A-MEM, and MemoryOS among its baselines. This makes LoCoMo a useful reference point for comparing long-conversation memory quality and recall behavior across systems.
In this LoCoMo evaluation, GUMem used less than half the average context tokens of Mem0 New, while reaching a 92.9% overall judge pass rate compared with Mem0 New's 91.6%. This shows that GUMem can reduce input context substantially while maintaining a higher overall answer correctness rate.
LongMemEval
LongMemEval is useful for evaluating long-term memory QA. It focuses on whether the system preserves stable facts across Sessions or long time spans and recalls the right context for a query.
Reports should distinguish:
- Whether Facts, Summary, and Topic generation finished before evaluation.
- Whether query uses only long-term memory or also recent Message context.
- Whether failures come from missing writes, missing recall, unused recall, or answer generation.
vs Mem0
When comparing against Mem0, do not only compare final answer score. GUMem is designed for retrievable, explainable, governable Memory, so reports should put answer quality, cost, provenance, and governance into the same table:
| Dimension | GUMem | Mem0 comparison basis | Report requirement |
|---|---|---|---|
| Answer quality | Generates answers after recalling Topic -> Summary -> Facts -> Message. | Use the same dataset, base model, judge prompt, and temperature. | Report answer correctness, recall hit rate, evidence quality, and failure categories. |
| Write path | Message input can produce Facts, Summary, and Topic. | Use the same write input and the same batch / async settings for Mem0. | Report write success rate, p50 / p95 latency, token cost, and embedding cost. |
| Query path | Narrows by Topic, retrieves Summary, then adds Facts and recent Message when needed. | Use the same query, top k, rerank, and context assembly strategy. | Report query p50 / p95 latency, returned context count, and whether the final answer used the context. |
| Provenance | Facts keep source Message references, and Summary should trace back to supporting Facts. | Check whether returned memory can be tied to the original write input. | Mark whether each answer can provide source Message input or equivalent evidence. |
| Governance and audit | Facts, Summary, and Topic can expose status, evidence, labels, and processing stage. | Check for equivalent memory state, evidence fields, and audit entry points. | Describe correction, archive, delete, demotion, and human review handling. |
| Extension points | WebHooks can add cleanup, audit, or sync logic during Facts, Summary, and Topic processing. | Check for equivalent extension points before write, around generation, or during query. | Document trigger timing, whether the hook affects the main path, and failure handling. |
If a public benchmark has not been finalized, do not publish unverified scores. Keep the reporting rubric and add numbers only after results are fixed.
Read and Write Performance
Write Path
GUMem writes are not a single insert. With long-term memory enabled, the write path is:
Message -> Facts -> Summary -> Topic| Stage | Performance impact |
|---|---|
| Message save | Usually light and mostly database-bound. |
| Facts extraction | Uses an LLM to read Message input and produce traceable facts. |
| Summary generation | Converts Facts into long-term memory. |
| Topic update | Assigns Summary to Topic and updates Topic text. |
| Vector write | Creates embeddings and writes retrieval indexes. |
Facts-only writes are shorter. Long-term writes improve future recall quality but add latency and cost.
Query Path
GUMem recalls memory by layer:
Topic -> Summary -> Facts -> Message| Stage | Performance impact |
|---|---|
| Query decision | Decides whether long-term memory is needed and whether the query should be rewritten. |
| Topic retrieval | Narrows the recall area. |
| Summary retrieval | Gets long-term memory usable by the Agent. |
| Facts backfill | Adds evidence when Summary is not enough. |
| Rerank | Improves relevance but adds latency. |
Common tuning parameters:
| Parameter | Description |
|---|---|
MessageRecentLimit | Maximum recent Message entries to include. |
MetadataFilters | A simple metadata key-value dictionary for exact recall filtering. |
Recommended Report Format
For any GUMem performance result, include:
- Write success rate and failure reasons.
- Query success rate and failure reasons.
- p50 / p95 / max write latency.
- p50 / p95 / max query latency.
- Recall hit rate, answer correctness, and evidence quality.
- Model, embedding provider, vector store, database, and hardware.
- Same configuration and dataset when comparing with Mem0 or other systems.
Next Step
Read Query Memory to understand how recall settings affect latency and result quality.