性能表现
Benchmark 类型
LoCoMo
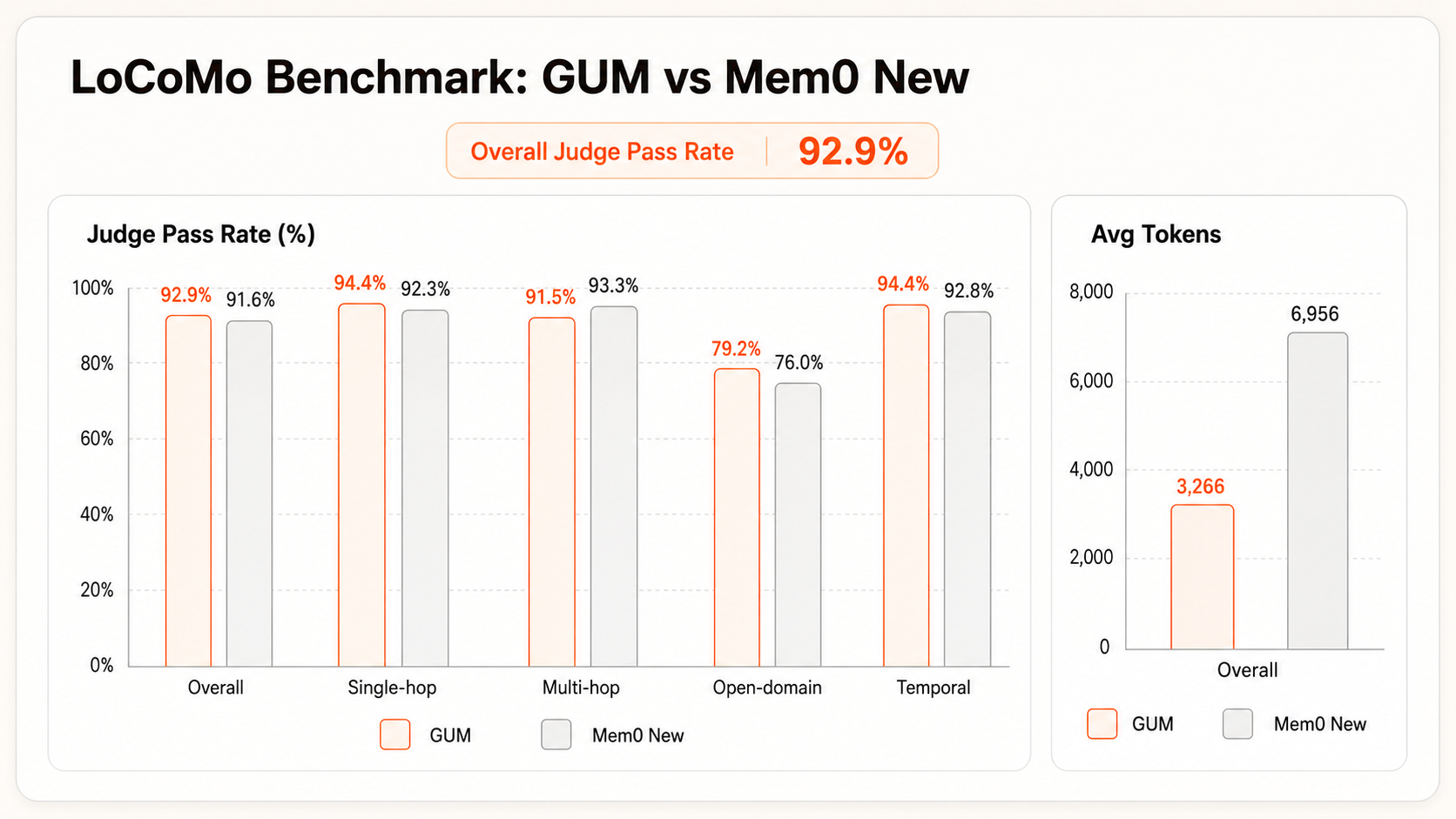
LoCoMo 是长对话记忆评估中常用的 benchmark,覆盖跨轮次、跨主题和时间相关问题,适合检验 Agent 能否从较长历史中召回稳定的用户事实和事件。Mem0 是目前较流行的 Agent Memory 产品之一,因此可以作为记忆召回效果和上下文成本的对比基线。
在本次 LoCoMo 评估中,GUMem 的平均上下文 token 低于 Mem0 New 的一半,但整体 Judge 通过率达到 92.9%,高于 Mem0 New 的 91.6%。这说明 GUMem 在显著减少输入上下文的同时,仍能保持更高的整体答案正确率。
| 项目 | 说明 |
|---|---|
| 数据集版本 | 使用的 LoCoMo 数据版本和样本范围。 |
| 写入策略 | 是否启用长期写入,是否写入 assistant 消息或行为 Message。 |
| 召回配置 | MessageRecentLimit 和 MetadataFilters,以及是否使用相同过滤条件。 |
| 评估指标 | 命中率、答案正确率、引用证据质量、失败类型。 |
| Judge 设置 | 使用的 judge model、prompt 和温度。 |
| 成本与延迟 | 每条样本写入成本、查询成本、p50 / p95 延迟。 |
LongMemEval
LongMemEval 适合评估长期记忆问答。它更强调系统能否在跨 Session 或长时间跨度中保留稳定事实,并在查询时找回相关上下文。
报告 LongMemEval 结果时,应区分:
- 写入阶段是否已经完成 Facts、Summary 和 Topic 生成。
- 查询阶段是否只使用长期记忆,还是同时使用近期 Message。
- 错误来自未写入、未召回、召回后未使用,还是生成答案时误用。
vs Mem0
与 Mem0 对比时,不能只比较最终答案分数。GUMem 的目标是可召回、可解释、可治理的 Memory,因此报告中应把答案质量、成本、来源追踪和治理能力放在同一张表中说明:
| 对比维度 | GUMem | Mem0 对比口径 | 报告要求 |
|---|---|---|---|
| 答案质量 | 按 Topic -> Summary -> Facts -> Message 召回后生成答案。 | 使用同一数据集、同一基础模型、同一 judge prompt 和温度。 | 报告答案正确率、召回命中率、证据质量和失败类型。 |
| 写入路径 | Message 写入后可继续生成 Facts、Summary 和 Topic。 | 使用 Mem0 的相同写入输入和相同 batch / async 设置。 | 报告写入成功率、p50 / p95 延迟、token 成本和 embedding 成本。 |
| 查询路径 | 先缩小 Topic 范围,再取回 Summary,必要时补充 Facts 和近期 Message。 | 使用相同 query、top k、rerank 和上下文拼接策略。 | 报告查询 p50 / p95 延迟、返回上下文数量和最终答案使用情况。 |
| 来源追踪 | Facts 保留来源 Message,Summary 应能回溯到支撑 Facts。 | 检查返回记忆是否能定位到原始写入内容。 | 标明每个答案是否能给出来源 Message 或等价证据。 |
| 治理与审计 | 可按 Facts / Summary / Topic 检查状态、证据、标签和处理阶段。 | 检查是否有等价的记忆状态、证据字段和审计入口。 | 说明更正、归档、删除、降权和人工审核的处理方式。 |
| 扩展点 | WebHooks 可在 Facts、Summary 和 Topic 处理节点加入清洗、审计或同步逻辑。 | 检查是否有等价的写入前、生成前后或查询阶段扩展能力。 | 说明扩展点触发时机、是否影响主链路、失败后如何处理。 |
如果某项公开 benchmark 尚未完成,不应在文档中给出未经验证的分数。页面应保留评估口径,等结果固定后再补充具体数字。
读写性能表现
写入路径
GUMem 写入不是一次简单 insert。启用长期记忆时,写入路径包括:
text
Message -> Facts -> Summary -> Topic主要耗时来自:
| 阶段 | 性能影响 |
|---|---|
| Message 保存 | 通常较轻,主要受数据库写入影响。 |
| Facts 抽取 | 需要 LLM 读取 Message,并生成有来源的事实。 |
| Summary 生成 | 需要把 Facts 转成可长期召回的记忆摘要。 |
| Topic 更新 | 需要把 Summary 归入 Topic,并更新 Topic 摘要。 |
| 向量写入 | 需要生成 embedding 并写入检索索引。 |
如果只启用 Facts 写入,写入链路会短一些;如果启用长期写入,召回质量更好,但写入延迟和成本更高。
查询路径
GUMem 查询按层级召回:
text
Topic -> Summary -> Facts -> Message主要耗时来自:
| 阶段 | 性能影响 |
|---|---|
| Query 判断 | 判断是否需要长期记忆,以及是否需要改写检索 query。 |
| Topic 检索 | 先缩小召回范围,减少后续噪声。 |
| Summary 检索 | 获取可直接用于 Agent 的长期记忆。 |
| Facts 补充 | 当 Summary 不足时补充证据层上下文。 |
| Rerank | 提升相关性,但会增加查询耗时。 |
常用调优参数:
| 参数 | 说明 |
|---|---|
MessageRecentLimit | 控制最多返回多少条近期 Message。 |
MetadataFilters | 简单的 metadata KV 字典,用于精确过滤召回范围。 |
推荐报告格式
发布任何 GUMem 性能结果时,建议同时给出:
- 写入成功率和失败原因。
- 查询成功率和失败原因。
- p50 / p95 / max 写入延迟。
- p50 / p95 / max 查询延迟。
- 召回命中率、答案正确率和证据质量。
- 模型、embedding、向量库、数据库和硬件环境。
- 与 Mem0 等系统对比时使用的相同配置和相同评估集。
下一步
阅读 查询记忆 了解召回参数如何影响延迟和结果质量。