GUMem 如何工作
GUMem 不是聊天记录数据库。它把原始 Message 加工成可追踪的 Facts,再生成适合长期召回的 Summary,并把 Summary 归入 Topic。查询时,GUMem 先通过 Topic 缩小范围,再取回 Summary;当 Summary 不足以支撑当前任务时,再补充 Facts 和原始 Message。
GUMem 的特点
| 特点 | 说明 |
|---|---|
| 分层记忆 | 原始输入、可追踪事实、长期摘要和主题入口分开管理,避免把完整历史无差别塞进 prompt。 |
| 有来源 | Facts 保留来源 Message,方便解释、审计、更正和删除。 |
| 只记录有依据的信息 | Facts 和 Summary 应来自明确输入,不把模型猜测写成用户事实。 |
| 支持长期召回 | 开启长期写入后,GUMem 会把 Facts 压缩成 Summary,并按 Topic 建立召回入口。 |
| 支持治理 | Summary 带有有效性、管理状态、置信度、时间、标签和证据字段,可用于归档、降权、删除和审计。 |
| 支持扩展 | WebHooks 可以在 Facts、Summary 和 Topic 的关键处理节点追加规则、清洗数据或同步外部系统。 |
记忆层次模型
GUMem 的公开模型按召回时的抽象层级理解:
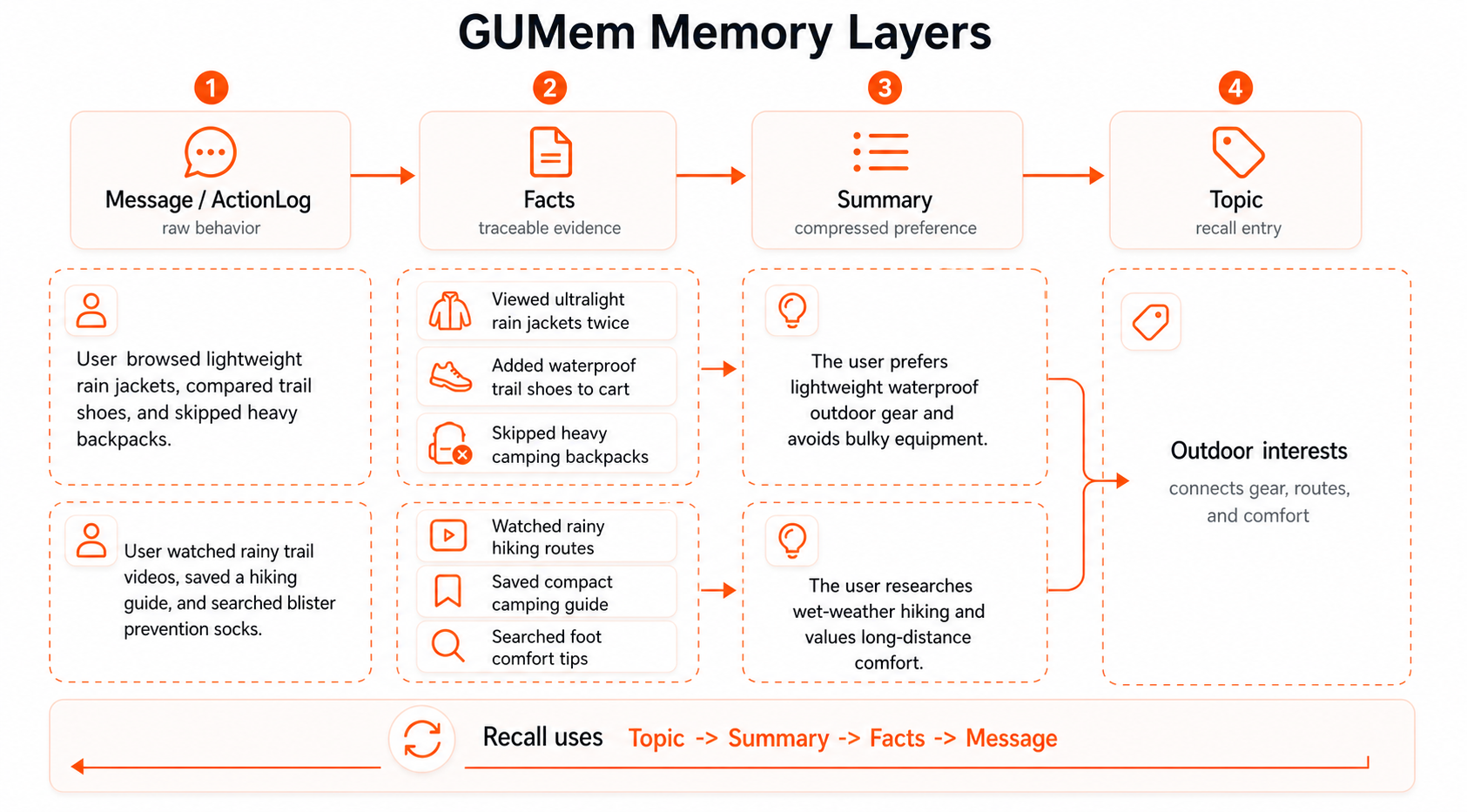
GUMem 用四层结构组织 Memory,是为了同时解决两个问题:记得足够多,又召回得足够准。
Message 保留原始输入,Facts 保留可追踪证据,Summary 提供可长期使用的压缩记忆,Topic 负责把记忆组织成可检索的方向。
写入时,信息从具体到抽象逐层沉淀;查询时,系统从抽象到具体逐层召回。这样 Agent 可以先找到相关主题,再拿到可用摘要,必要时回到事实和原始消息验证来源。
| 层级 | 作用 | 示例 |
|---|---|---|
Topic | 高层主题,用于找到相关记忆区域。 | team scheduling |
Summary | 可长期召回的压缩记忆,由一组 Facts 支撑。 | 用户偏好欧洲团队排期默认使用 Berlin。 |
Facts | 从 Message 中抽取出的可追踪事实、偏好、计划或约束。 | 用户说过 Europe 对应 Berlin,Americas 对应 Toronto。 |
Message | 原始对话消息或行为输入。 | 用户原始消息、搜索、筛选、收藏或工具调用结果。 |
记忆提取
GUMem 按层级完成记忆提取:先抽取高保真的 Facts,再基于同一批 Facts 生成多角度 Summaries,最后迭代更新 Topics,让长期记忆保持可追踪、可压缩和可召回。
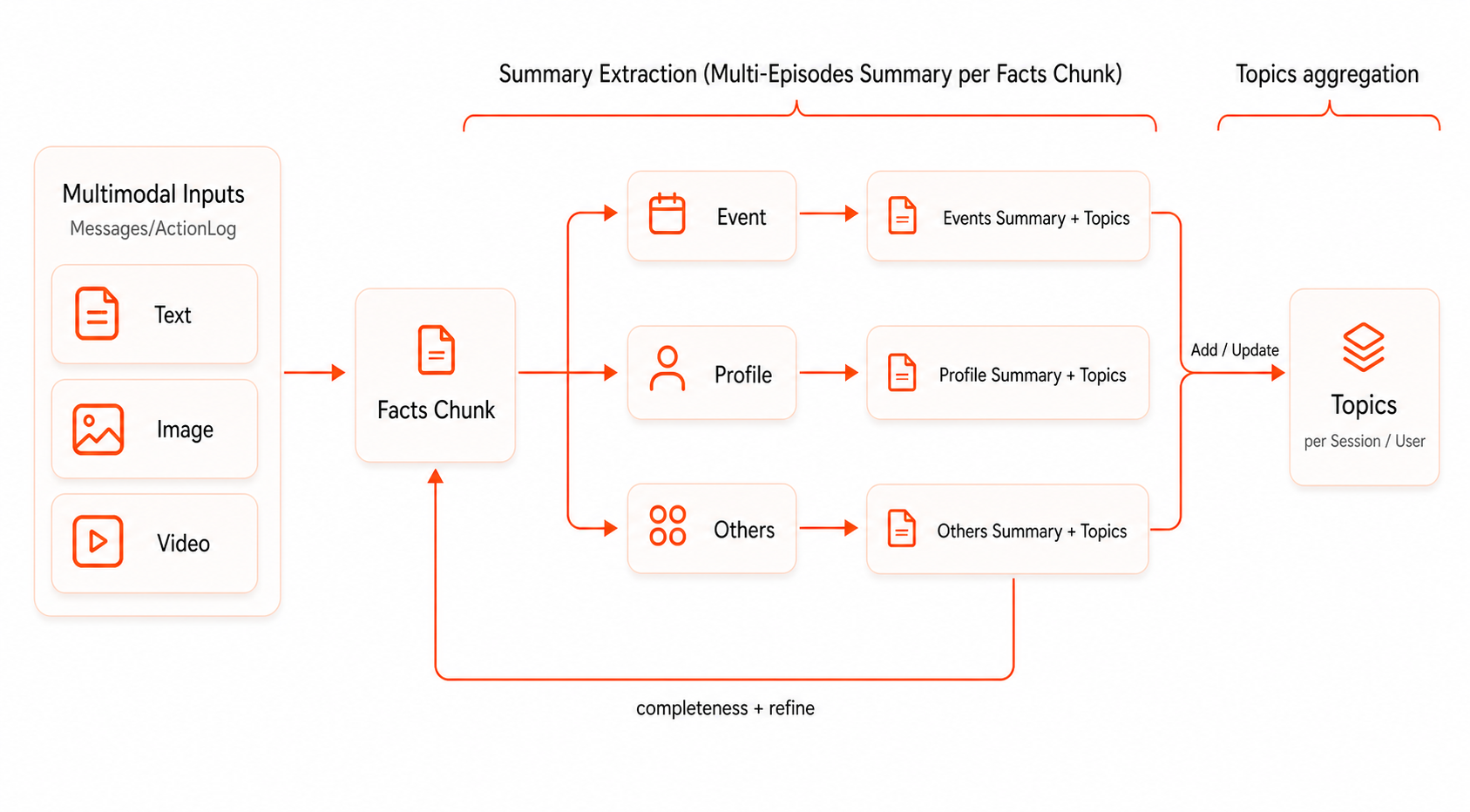
- Facts 抽取:从原始输入中提取明确支持的信息,重点保证准确性、低噪声和高保真。系统会保留关键实体、明确指代、来源证据和绝对时间锚点,不把推测或补全写成事实。
- Summaries 抽取:基于同一批 Facts Chunk 做多角度抽象、归纳和直接推理,将分散事实压缩成适合 Agent 使用的长期上下文。
- Topics 更新:根据新生成的 Summaries 和已有 Topic 内容迭代更新主题入口,保持长期记忆的新鲜度和召回效率。
如果关闭长期记忆写入,GUMem 会停在 Facts 层,不继续生成 Summary 和 Topic。这适合只需要可审计事实、暂不需要跨 Session 长期召回的场景。
记忆的召回
GUMem 的召回按记忆层级逐步展开。系统会先从 Topic 定位相关记忆范围;如果高层结果已经足够,就直接进入返回流程。当 Topic 的召回内容不足时,系统会继续下钻到 Summary,获取更具体的长期记忆;如果 Summary 仍不足以支撑当前任务,再继续补充 Facts 作为证据层上下文。
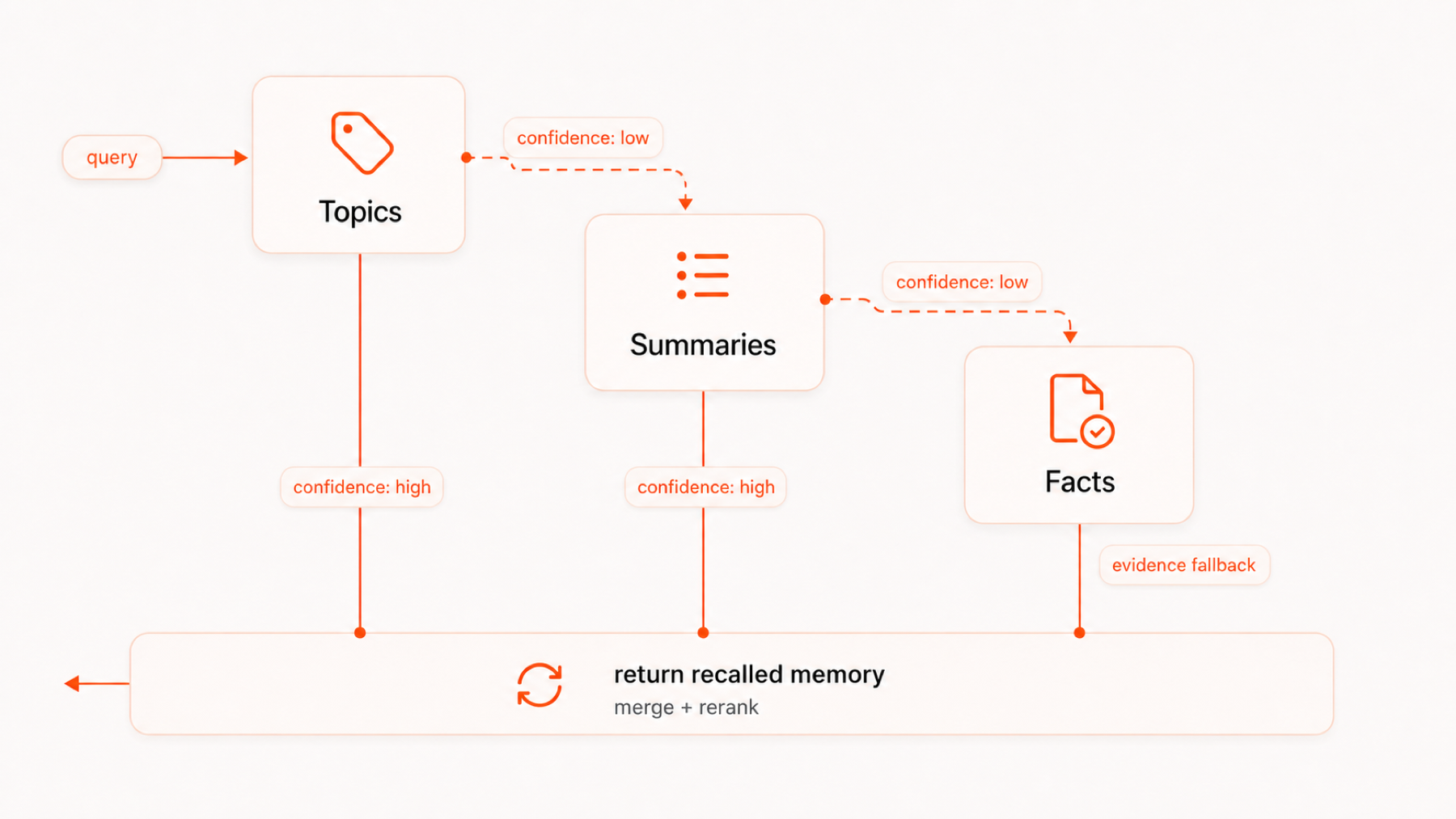
这张图可以按以下顺序理解:
- Topic 定位方向:
query先进入Topics,用高层主题快速缩小召回范围。 - Summary 补充记忆:如果
confidence: low,系统继续召回Summaries,拿到更具体的压缩记忆。 - Facts 补充证据:如果 Summary 仍然不够,系统再下钻到
Facts,补充可追踪证据。 - merge + rerank 返回结果:召回得到的候选内容会先合并,再按当前 query 的相关性、置信度和证据强度重新排序,最终返回给 Agent 使用。
这让召回过程既能保持高层检索的效率,也能在上下文不足时回到更细粒度的事实层,避免把所有历史一次性塞进上下文。
Memory Layers
Topic
Topic 是 Summary 的高层组织层,也是长期召回的第一入口。它通常代表稳定的画像维度、业务主题或任务领域。
Topic 的特点:
- 它用于召回,不是用户可见的目录。
- 一个 Topic 可以关联多条 Summary。
- Topic 会保留自己的 summary text,帮助召回找到正确区域。
- Topic 应来自允许的主题集合,避免主题无限膨胀。
Summary
Summary 是由 Facts 支撑的长期记忆摘要。它比原始 Message 更短,比单条 Fact 更适合被 Agent 在后续任务中直接使用。
Summary 的特点:
- 内容必须能被来源 Facts 支撑。
- 可以带有置信度、标签、实体和事件时间。
- 支持
active、deprioritized、archived、deleted这类管理状态。 - 支持检索加权、访问统计和后续治理。
- 用户更正信息时,应通过新的 Message 形成新的 Facts 和 Summary,而不是把旧 Summary 当成不可变真相。
Facts
Facts 是从 Message 中抽取出的可追踪事实、偏好、计划、约束、事件或行为信号。Facts 是解释和治理的证据层。
Facts 的特点:
- 必须能追溯到一个或多个来源 Message。
- 会保留时间范围、实体、标签和证据信息。
- 只表达输入中明确支持的信息,不补全缺失细节。
- 可以从用户、assistant 或 system 的消息中产生,但必须准确保留说话者和语气。
- 当用户更新旧信息时,Facts 会记录新的状态和变化来源。
Message
Message 是 GUMem 的原始输入。它可以是用户、assistant 或 system 的对话消息,也可以是上游系统整理后的行为文本或业务事件描述。
Message 的特点:
- 至少包含
role和content。 - 可以携带
metadata、timestamp、turn_id和处理状态。 - 是 Facts 的来源,不等同于最终长期记忆。
- 写入时应带上足够的时间和业务上下文,方便后续解释和审计。
失败和边界
- 不要把 GUMem 当成强一致业务数据库。订单、权限、账单、库存等数据仍应由业务系统负责。
- 不要把未确认推断写成 Facts。证据不足时,应向用户确认。
- 不要默认长期保存所有输入。只写入会影响未来回答、推荐、工具调用或风险判断的信息。
- 不要把 Summary 当成不可更改的真相。用户更正后,应写入新的 Message,让 GUMem 形成新的事实链路。